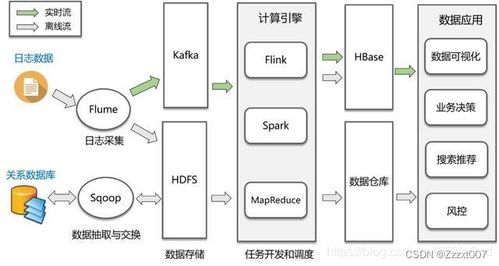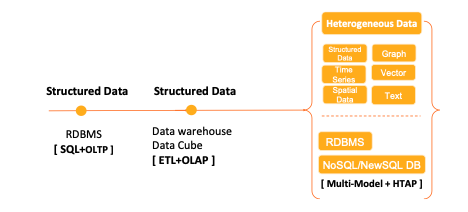
數(shù)據(jù)庫系統(tǒng)是現(xiàn)代信息社會的基石,其演進(jìn)歷程深刻反映了計算模式、業(yè)務(wù)需求和技術(shù)創(chuàng)新的變遷。特別是在支持在線數(shù)據(jù)處理(OLAP)與在線交易處理(OLTP)這兩類核心業(yè)務(wù)的過程中,數(shù)據(jù)庫技術(shù)經(jīng)歷了從單一到分離,再到融合與創(chuàng)新的螺旋式發(fā)展。
第一階段:關(guān)系型數(shù)據(jù)庫的興起與OLTP的統(tǒng)治(1970s-1990s)
數(shù)據(jù)庫系統(tǒng)的現(xiàn)代演進(jìn)始于關(guān)系模型的提出。以IBM的System R和加州大學(xué)的INGRES為代表,關(guān)系型數(shù)據(jù)庫管理系統(tǒng)(RDBMS)憑借其嚴(yán)謹(jǐn)?shù)臄?shù)學(xué)基礎(chǔ)(關(guān)系代數(shù)與演算)、清晰的結(jié)構(gòu)(表、行、列)和非過程化的查詢語言(SQL),迅速成為主流。這一時期,數(shù)據(jù)庫的核心使命是高效、可靠地處理企業(yè)的日常業(yè)務(wù)交易,即在線交易處理(OLTP)。OLTP業(yè)務(wù)的特點(diǎn)是高頻、短小、原子性的讀寫操作(如銀行轉(zhuǎn)賬、訂單錄入),強(qiáng)調(diào)數(shù)據(jù)的一致性(C)、事務(wù)的原子性(A)、隔離性(I)和持久性(D),即嚴(yán)格的ACID屬性。技術(shù)焦點(diǎn)集中在鎖機(jī)制、日志恢復(fù)和緩沖區(qū)管理上,以保障在并發(fā)訪問下數(shù)據(jù)的準(zhǔn)確無誤。代表性的商業(yè)數(shù)據(jù)庫如Oracle、DB2、SQL Server均在此階段奠定霸主地位,架構(gòu)上多為垂直擴(kuò)展的單體系統(tǒng)。
第二階段:數(shù)據(jù)倉庫的誕生與OLAP的分離(1990s-2000s)
隨著企業(yè)數(shù)據(jù)量的積累,管理層不再滿足于僅處理當(dāng)前交易,更希望從歷史數(shù)據(jù)中分析趨勢、輔助決策。這催生了在線分析處理(OLAP) 需求。OLAP業(yè)務(wù)涉及對海量歷史數(shù)據(jù)的復(fù)雜查詢、多維度聚合和批量計算(如季度銷售報表、客戶行為分析),特點(diǎn)是查詢復(fù)雜、數(shù)據(jù)掃描量大、但時效性要求相對寬松。
直接將OLAP查詢運(yùn)行在OLTP數(shù)據(jù)庫上會產(chǎn)生嚴(yán)重沖突:復(fù)雜的分析查詢會消耗大量I/O和CPU資源,長時間鎖表,進(jìn)而拖垮關(guān)鍵的交易業(yè)務(wù)。為此,數(shù)據(jù)倉庫(Data Warehouse) 概念應(yīng)運(yùn)而生。其核心思想是架構(gòu)分離:將OLTP系統(tǒng)產(chǎn)生的業(yè)務(wù)數(shù)據(jù),通過ETL(抽取、轉(zhuǎn)換、加載)過程,定期導(dǎo)入一個獨(dú)立的、針對分析優(yōu)化的數(shù)據(jù)庫中。這個分析數(shù)據(jù)庫采用不同的數(shù)據(jù)模型(如星型模式、雪花模式),并利用預(yù)計算(如物化視圖)、列式存儲(早期探索)和專門的索引技術(shù)來加速查詢。這一階段,數(shù)據(jù)庫系統(tǒng)在功能上出現(xiàn)了清晰的讀寫分離和庫倉分離,Teradata、Netezza等專用數(shù)據(jù)倉庫設(shè)備獲得成功。
第三階段:互聯(lián)網(wǎng)時代與NoSQL/NewSQL的沖擊(2000s-2010s)
Web 2.0和移動互聯(lián)網(wǎng)的爆發(fā)帶來了數(shù)據(jù)特征的劇變:數(shù)據(jù)量(Volume)、速度(Velocity)、多樣性(Variety)的“3V”挑戰(zhàn)。傳統(tǒng)關(guān)系數(shù)據(jù)庫在應(yīng)對海量用戶并發(fā)、半結(jié)構(gòu)化/非結(jié)構(gòu)化數(shù)據(jù)存儲、以及需要跨數(shù)據(jù)中心分布時顯得力不從心。
為了滿足可擴(kuò)展性和靈活性,NoSQL數(shù)據(jù)庫浪潮興起。它們通常犧牲嚴(yán)格的ACID事務(wù)(追求最終一致性BASE理論)和復(fù)雜SQL功能,以換取水平擴(kuò)展、高可用性和靈活的數(shù)據(jù)模型(鍵值對、文檔、列族、圖)。這類數(shù)據(jù)庫很好地支撐了互聯(lián)網(wǎng)規(guī)模的OLTP類應(yīng)用(如用戶會話、商品目錄、社交圖譜)。為了兼顧SQL的易用性與NoSQL的可擴(kuò)展性,NewSQL數(shù)據(jù)庫出現(xiàn),它們試圖在分布式架構(gòu)下重新實(shí)現(xiàn)ACID事務(wù),例如Google Spanner、CockroachDB。
在OLAP領(lǐng)域,Hadoop生態(tài)(HDFS, MapReduce, Hive)利用廉價硬件集群處理超大規(guī)模數(shù)據(jù)分析,但其批處理模式延遲較高。MPP(大規(guī)模并行處理) 架構(gòu)的數(shù)據(jù)倉庫/數(shù)據(jù)湖解決方案(如Amazon Redshift, Google BigQuery, Snowflake)將云與列式存儲結(jié)合,提供了強(qiáng)大的彈性O(shè)LAP能力。
第四階段:云原生、混合負(fù)載與實(shí)時化的融合(2010s至今)
當(dāng)前,數(shù)據(jù)庫演進(jìn)進(jìn)入云原生與智能化時代。業(yè)務(wù)需求呈現(xiàn)兩大趨勢:
- 實(shí)時決策需求:企業(yè)希望在同一份最新的數(shù)據(jù)上同時進(jìn)行交易和實(shí)時分析,例如在金融反欺詐中,需要在交易發(fā)生的瞬間進(jìn)行風(fēng)險分析。這模糊了OLTP與OLAP的傳統(tǒng)界限。
- 數(shù)據(jù)價值最大化:減少數(shù)據(jù)移動和復(fù)制成本,實(shí)現(xiàn)更簡化的數(shù)據(jù)架構(gòu)。
為此,技術(shù)發(fā)展呈現(xiàn)融合態(tài)勢:
- 云原生數(shù)據(jù)庫:如AWS Aurora、Azure SQL Database,將計算與存儲分離,實(shí)現(xiàn)彈性伸縮、高可用和按需付費(fèi),同時兼容傳統(tǒng)SQL和事務(wù)模型。
- HTAP數(shù)據(jù)庫:混合事務(wù)/分析處理(HTAP) 成為重要方向。這類數(shù)據(jù)庫(如Google Spanner, TiDB, Oracle Autonomous Database)旨在用一個數(shù)據(jù)庫引擎同時高效處理OLTP和OLAP負(fù)載。其關(guān)鍵技術(shù)包括行列混合存儲、智能數(shù)據(jù)分區(qū)、以及基于快照隔離的讀寫分離,使得分析查詢可以在不影響事務(wù)處理的前提下,訪問一致性的實(shí)時數(shù)據(jù)快照。
- 實(shí)時分析數(shù)據(jù)庫:針對流數(shù)據(jù)的流處理與批處理的邊界也在模糊,出現(xiàn)了流批一體的架構(gòu)(如Apache Flink),支持對無限數(shù)據(jù)流進(jìn)行實(shí)時OLAP。
- AI增強(qiáng):機(jī)器學(xué)習(xí)被用于數(shù)據(jù)庫內(nèi)核的自動優(yōu)化(索引推薦、查詢調(diào)優(yōu))、成本預(yù)測和自治運(yùn)維。
數(shù)據(jù)庫系統(tǒng)的演進(jìn),圍繞OLTP與OLAP這兩大業(yè)務(wù)支柱,走過了從“一體”到“分離”,再到追求“智能融合”的道路。驅(qū)動力量從早期的理論創(chuàng)新、中期的規(guī)模化挑戰(zhàn),發(fā)展到今天的云化、實(shí)時化和智能化需求。未來的數(shù)據(jù)庫將不再是單一功能的系統(tǒng),而是向著融合、自治、多模、云原生的方向發(fā)展,為企業(yè)提供一個能夠無縫支持從實(shí)時交易到深度分析的全數(shù)據(jù)價值鏈處理平臺。